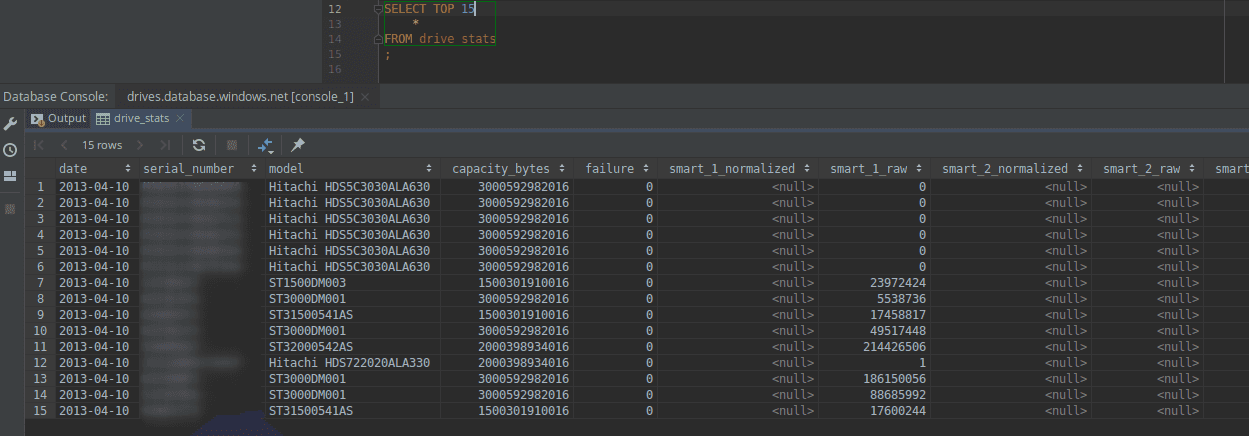
Moving files with Azure Data Factory
The storage and backup company Backblaze publishes some neat data on hard drive reliability. My purpose today is to create an Azure Data Factory that reads these raw files and uploads them to Azure SQL.
Data Schema
Backblaze provides a schema for use, that I edited the data types slightly to fit Azure SQL and Data Factory better. Each of the provided data files in year 2013 follow this format.
CREATE TABLE drive_stats (
date DATE NOT NULL,
serial_number NVARCHAR(MAX) NOT NULL,
model NVARCHAR(MAX) NOT NULL,
capacity_bytes BIGINT NOT NULL,
failure INTEGER NOT NULL,
smart_1_normalized INTEGER,
smart_1_raw INTEGER,
smart_2_normalized INTEGER,
smart_2_raw INTEGER,
smart_3_normalized INTEGER,
smart_3_raw INTEGER,
smart_4_normalized INTEGER,
smart_4_raw INTEGER,
smart_5_normalized INTEGER,
smart_5_raw INTEGER,
smart_7_normalized INTEGER,
smart_7_raw INTEGER,
smart_8_normalized INTEGER,
smart_8_raw INTEGER,
smart_9_normalized INTEGER,
smart_9_raw INTEGER,
smart_10_normalized INTEGER,
smart_10_raw INTEGER,
smart_11_normalized INTEGER,
smart_11_raw INTEGER,
smart_12_normalized INTEGER,
smart_12_raw INTEGER,
smart_13_normalized INTEGER,
smart_13_raw INTEGER,
smart_15_normalized INTEGER,
smart_15_raw INTEGER,
smart_183_normalized INTEGER,
smart_183_raw INTEGER,
smart_184_normalized INTEGER,
smart_184_raw INTEGER,
smart_187_normalized INTEGER,
smart_187_raw INTEGER,
smart_188_normalized INTEGER,
smart_188_raw INTEGER,
smart_189_normalized INTEGER,
smart_189_raw INTEGER,
smart_190_normalized INTEGER,
smart_190_raw INTEGER,
smart_191_normalized INTEGER,
smart_191_raw INTEGER,
smart_192_normalized INTEGER,
smart_192_raw INTEGER,
smart_193_normalized INTEGER,
smart_193_raw INTEGER,
smart_194_normalized INTEGER,
smart_194_raw INTEGER,
smart_195_normalized INTEGER,
smart_195_raw INTEGER,
smart_196_normalized INTEGER,
smart_196_raw INTEGER,
smart_197_normalized INTEGER,
smart_197_raw INTEGER,
smart_198_normalized INTEGER,
smart_198_raw INTEGER,
smart_199_normalized INTEGER,
smart_199_raw INTEGER,
smart_200_normalized INTEGER,
smart_200_raw INTEGER,
smart_201_normalized INTEGER,
smart_201_raw INTEGER,
smart_223_normalized INTEGER,
smart_223_raw INTEGER,
smart_225_normalized INTEGER,
smart_225_raw INTEGER,
smart_240_normalized INTEGER,
smart_240_raw INTEGER,
smart_241_normalized INTEGER,
smart_241_raw INTEGER,
smart_242_normalized INTEGER,
smart_242_raw INTEGER,
smart_250_normalized INTEGER,
smart_250_raw INTEGER,
smart_251_normalized INTEGER,
smart_251_raw INTEGER,
smart_252_normalized INTEGER,
smart_252_raw INTEGER,
smart_254_normalized INTEGER,
smart_254_raw INTEGER,
smart_255_normalized INTEGER,
smart_255_raw INTEGER
);Azure Resources
I have an Azure SQL Database, an Azure Data Factory, and an Azure Storage Account setup in one resource group for today’s purposes.
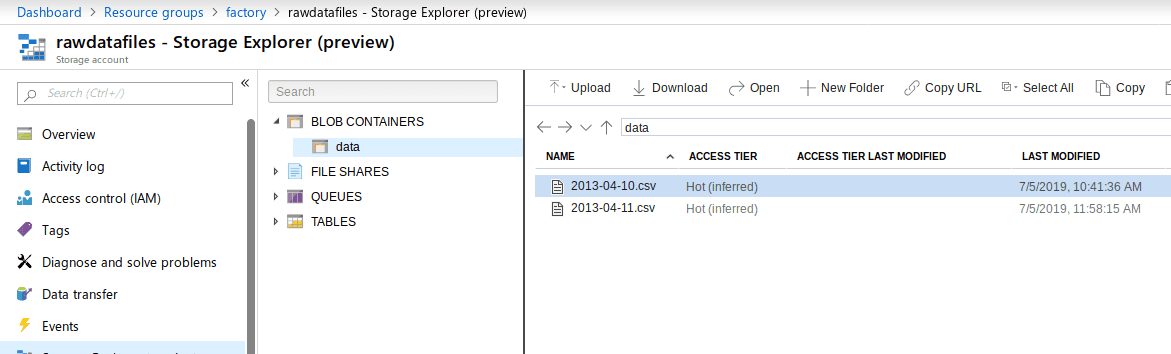
File Storage
I am uploading the files to blobs in the Azure storage account. Here are the first two delimited files uploaded.
Data Factory V2
The new data factory doesn’t have anything yet and just shows the quickstart.
Adding Git Storage
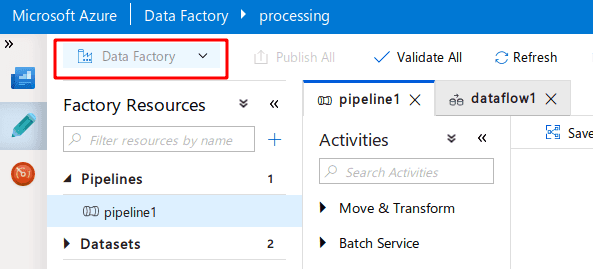
The first thing I’m going to do is to click on the pencil and then the dropdown here to select a new git repository.
I have an empty Azure DevOps repo ready.
Azure Data Factory can point to this repo to store settings and information, which allows for git collaboration.
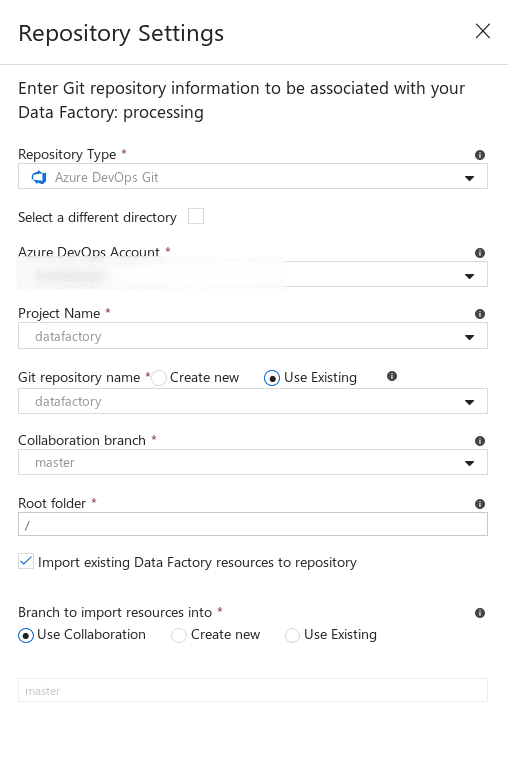
There wouldn’t be any data yet in an empty project, but this is what it might look like later.
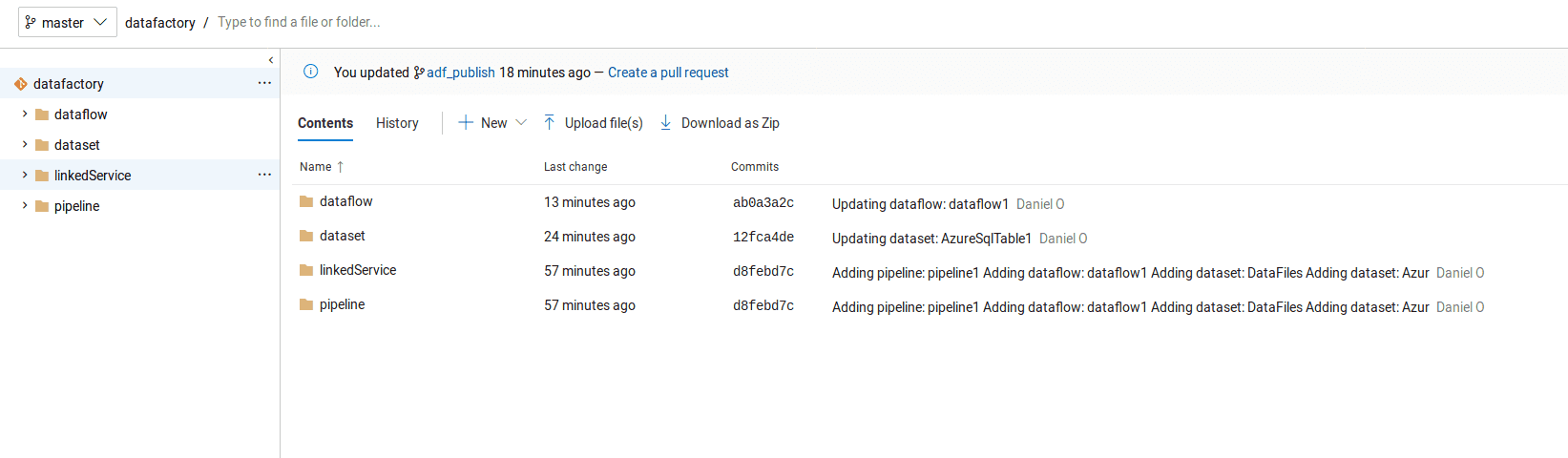
Back in Data Factory, you’ll see the option to switch branches which is handy for feature branches.
Datasets
I’m going to create two new datasets, one for Azure SQL and one for Azure Blob Storage.
Blob
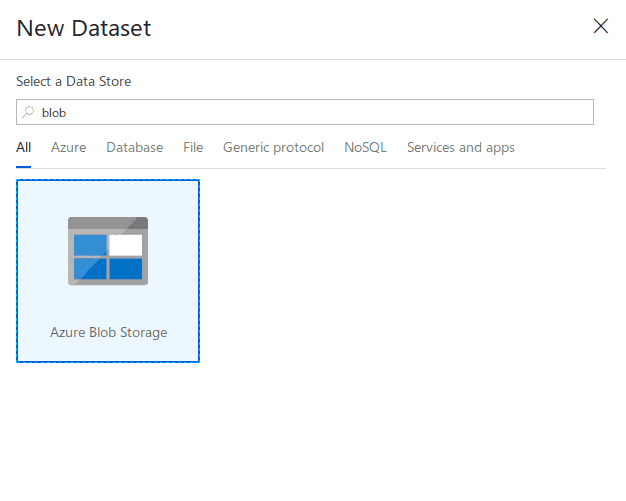
Click on the plus-sign on the Factory Resources and select Dataset. A side window will appear where you can search through connectors and pick Blob.
Pick delimited
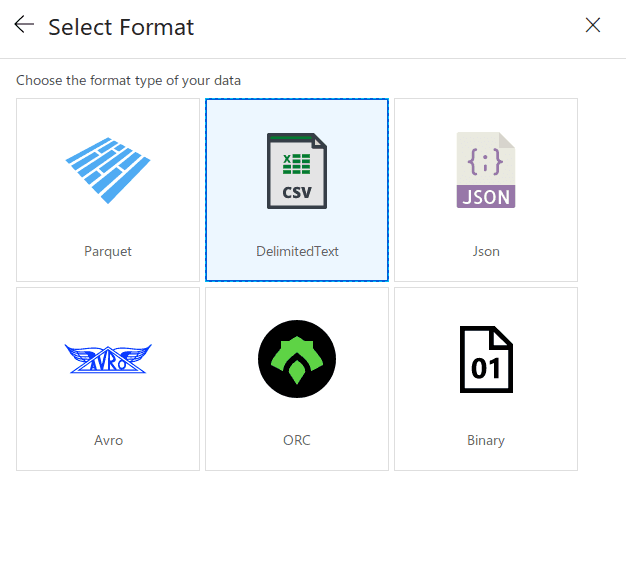
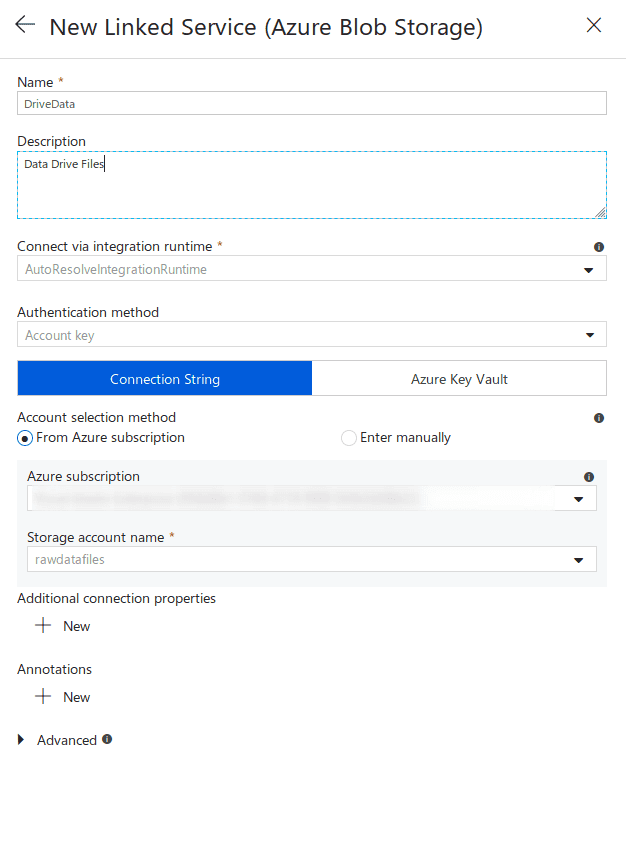
Next on blob properties, say the first row has the header, and then link a new service.
The new linked service window will look like this
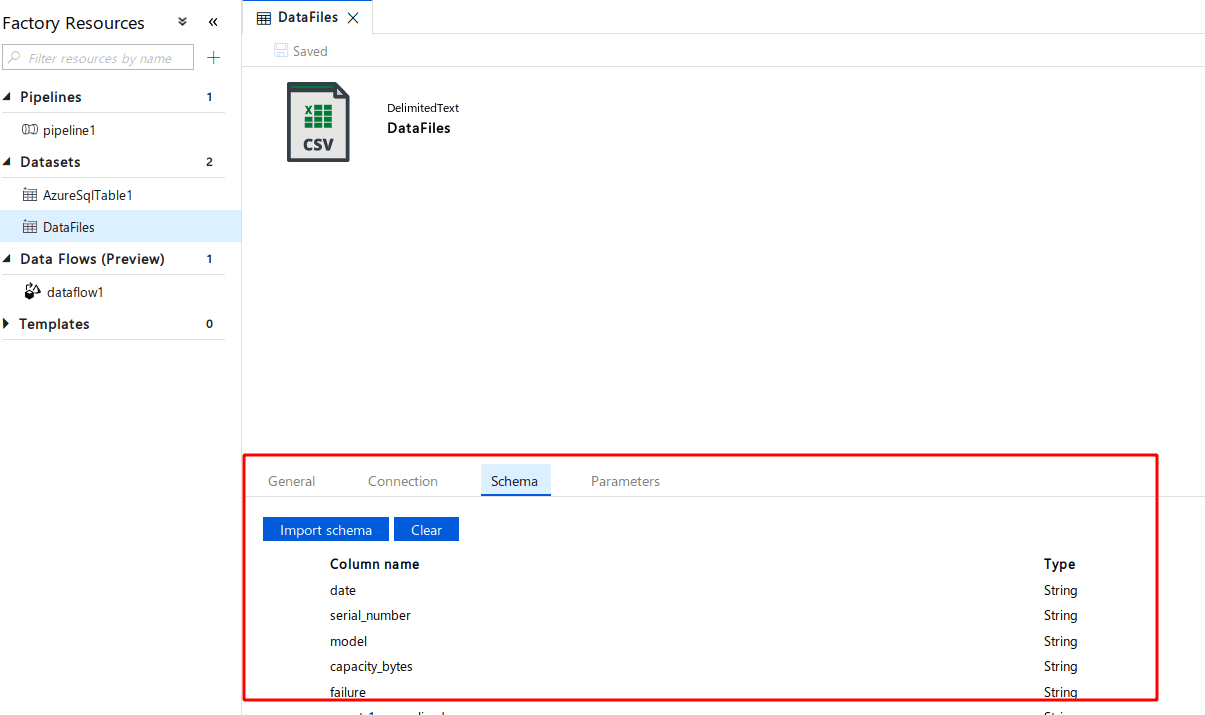
Allow the service to import schema from connection, which will use one of the data files uploaded to infer the schema.
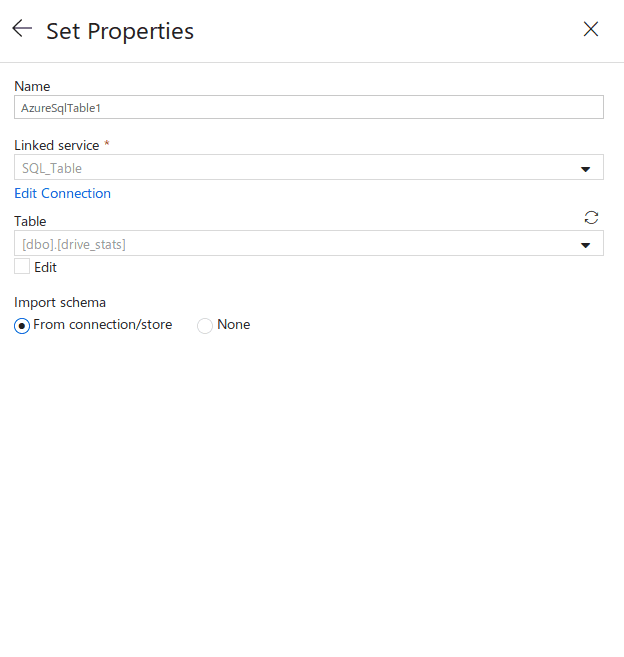
SQL
The Azure SQL setup dataset is very similar to the Blob Storage.
The schema comes from the SQL defined far above.
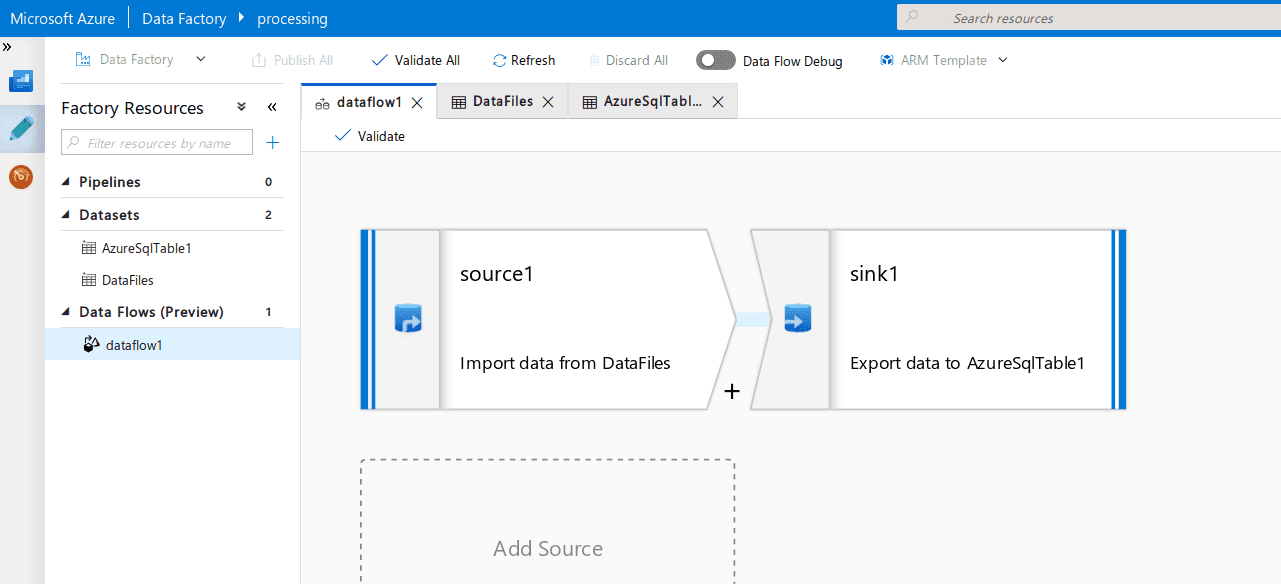
Dataflow
To move data from Blobs to SQL, I’ve created a dataflow that uses Blob storage as a source, and SQL as a sink.
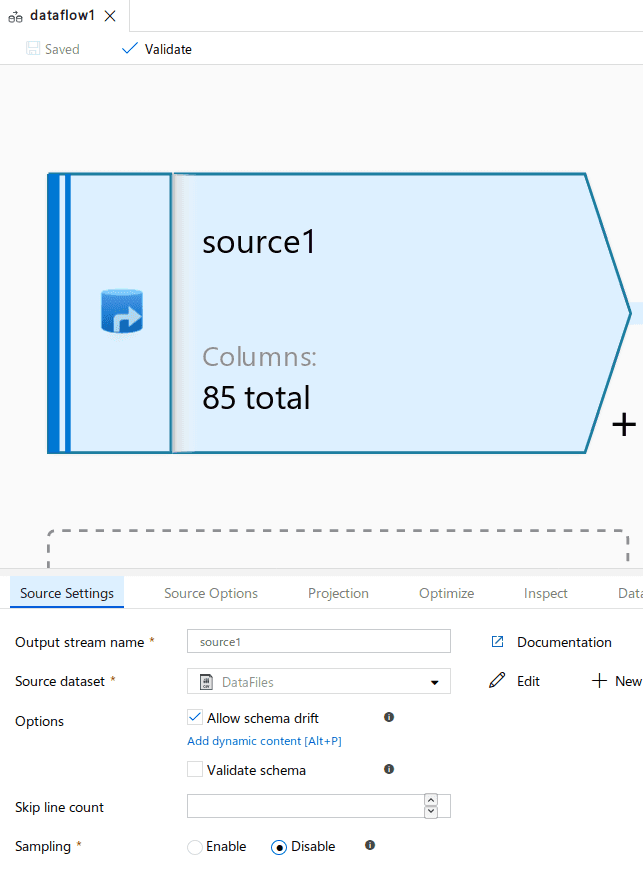
Source:
Sink:

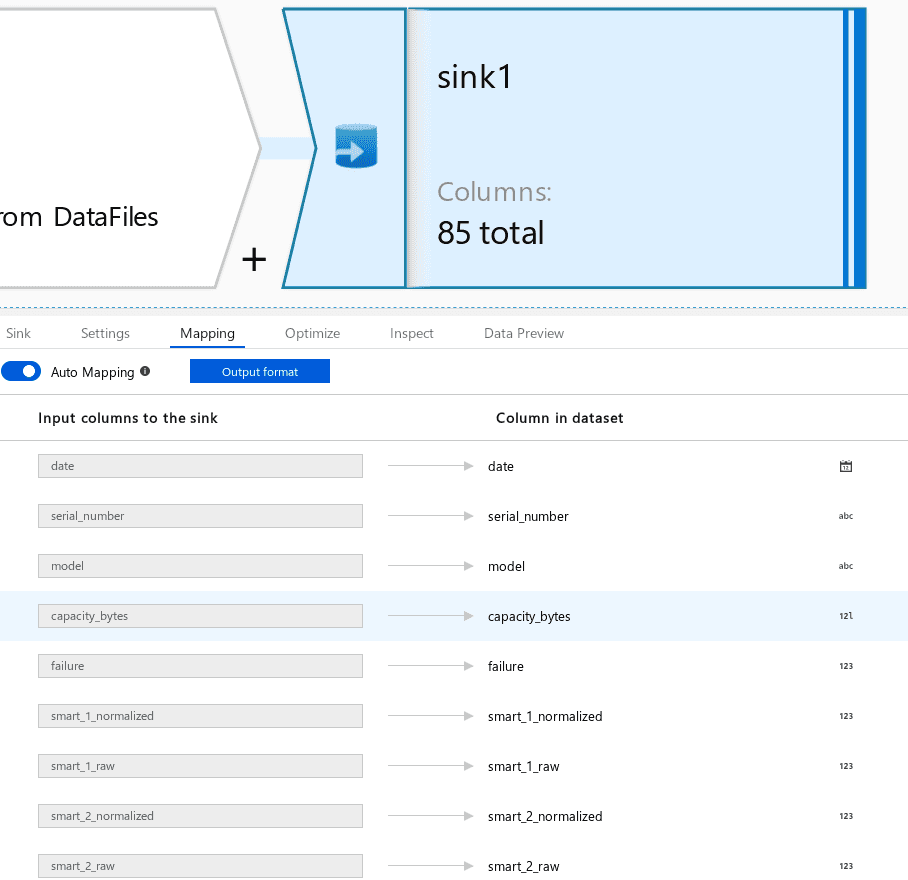
Projection of the source data is necessary so that the source’s data types will match the sink’s data types.
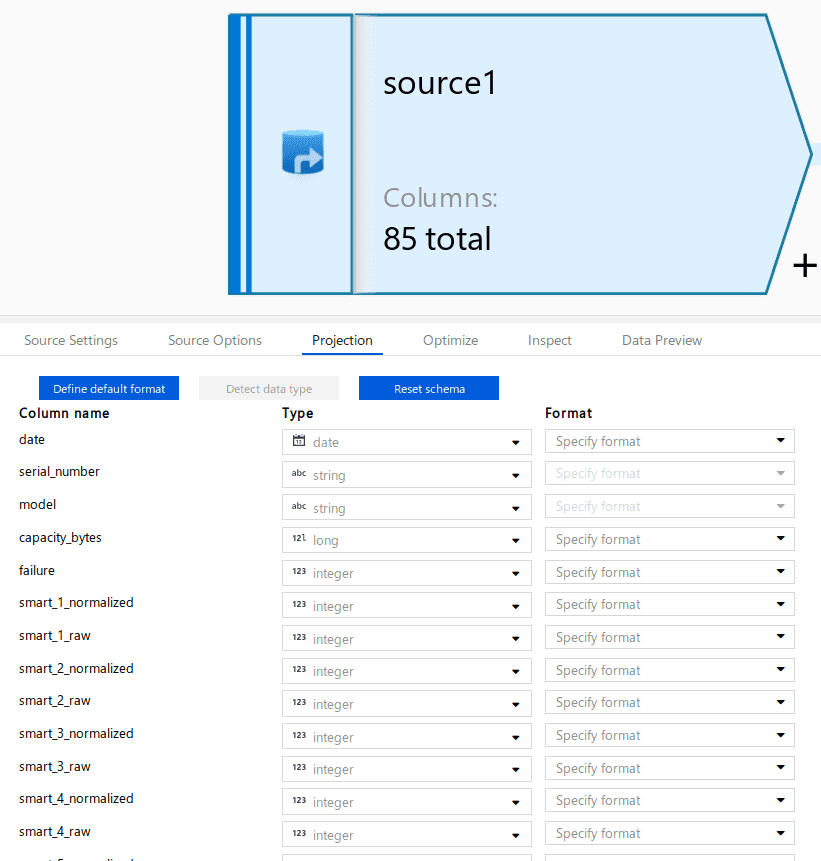
Once data types and names match, the source and the sink can be automapped.
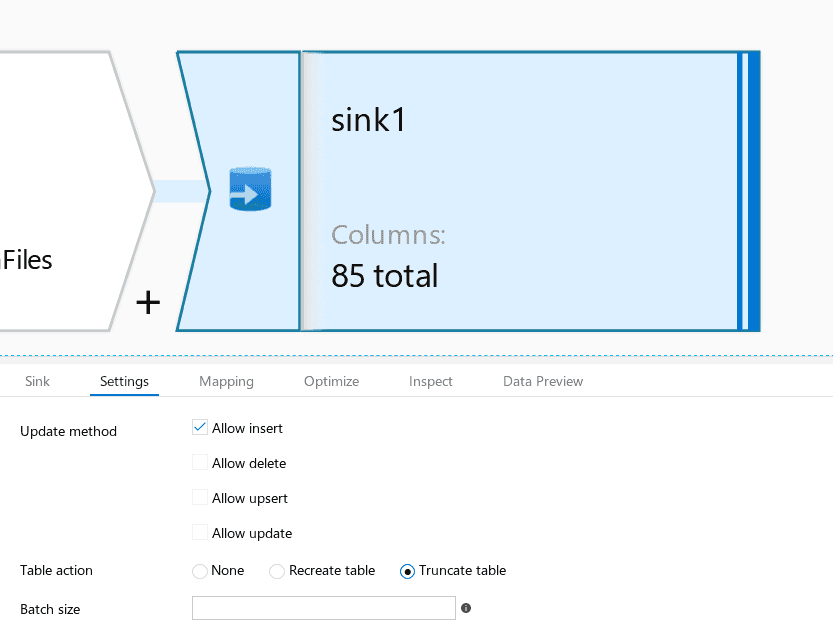
The sink has settings that allow the table to be truncated and new rows inserted. I’m rebuilding the entire table’s data from scratch.
Running
Now that I have a dataflow, I’ve created a new pipeline and added a single task to it.
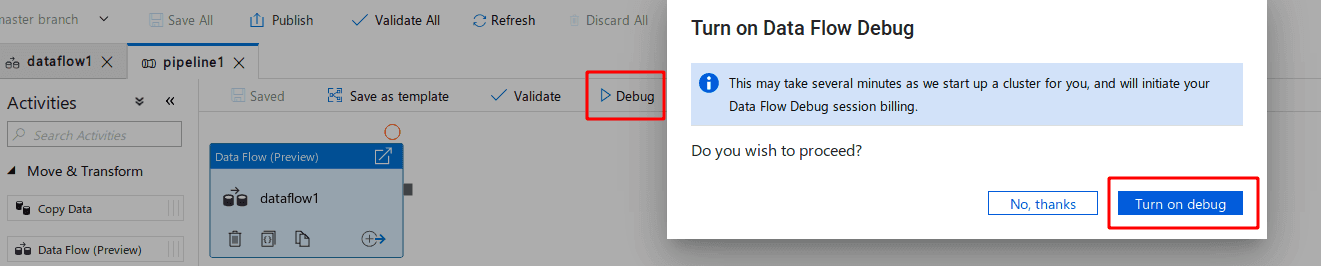
Click the debug and let’s run this!
Debug status will be at the bottom of the screen.
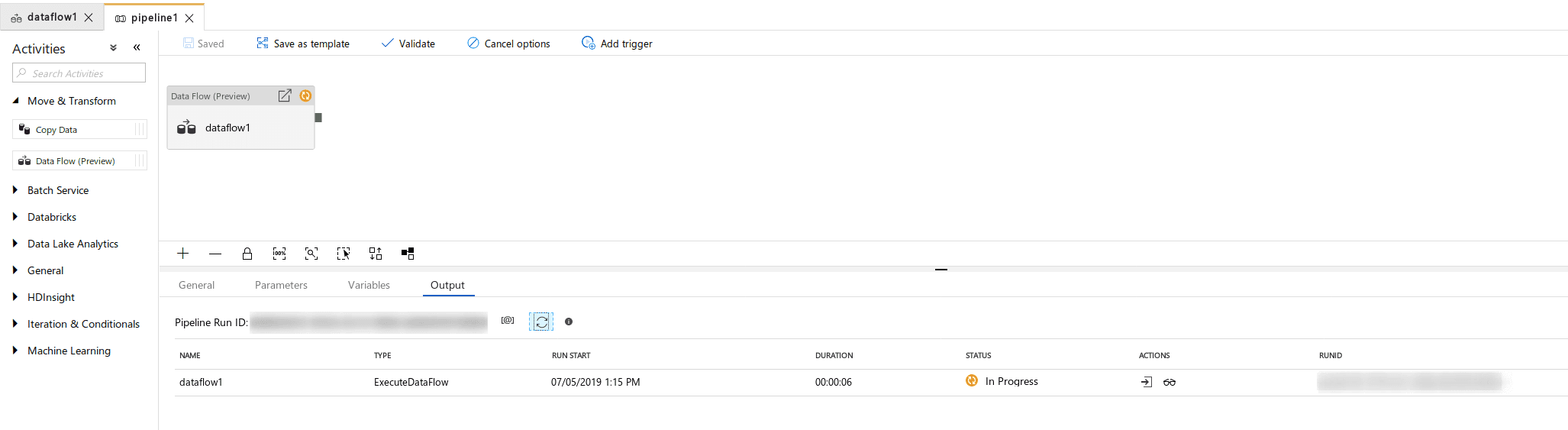
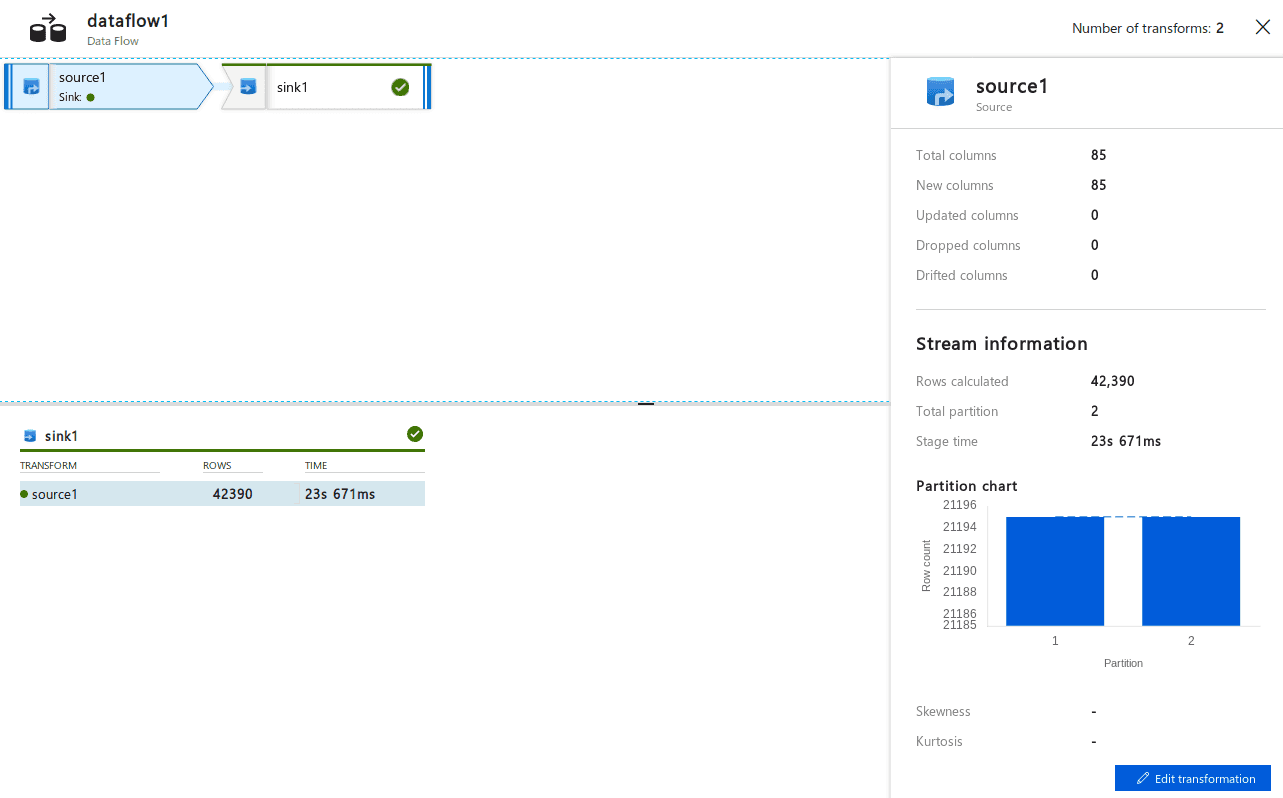
Upon success, look at the details page found here:

I can see that a total of 42,390 rows were found in the source.
Summary
I have a working pipeline that moves data from delimited files to SQL, and below is a sample of a few rows from SQL. To make this automatic, perhaps adding a trigger to execute on blob creation would be good. To continue on with continuous integration, I’d follow this document for comprehensive guide. I’ve also created a second blog post to do it simply with PowerShell.